Saddle Point Gradient - Intro to optimization in deep learning: Momentum, RMSProp
Other techniques would need to be used to classify the critical point. Mar 01, 2018 · as you can see in the image below, the gradients can be very small at a saddle point. Three sets of gradient coils are used in nearly all mr systems: If \(d = 0\) then the point \(\left( {a,b} \right)\) may be a relative minimum, relative maximum or a saddle point. It can be useful to increase the learning rate …
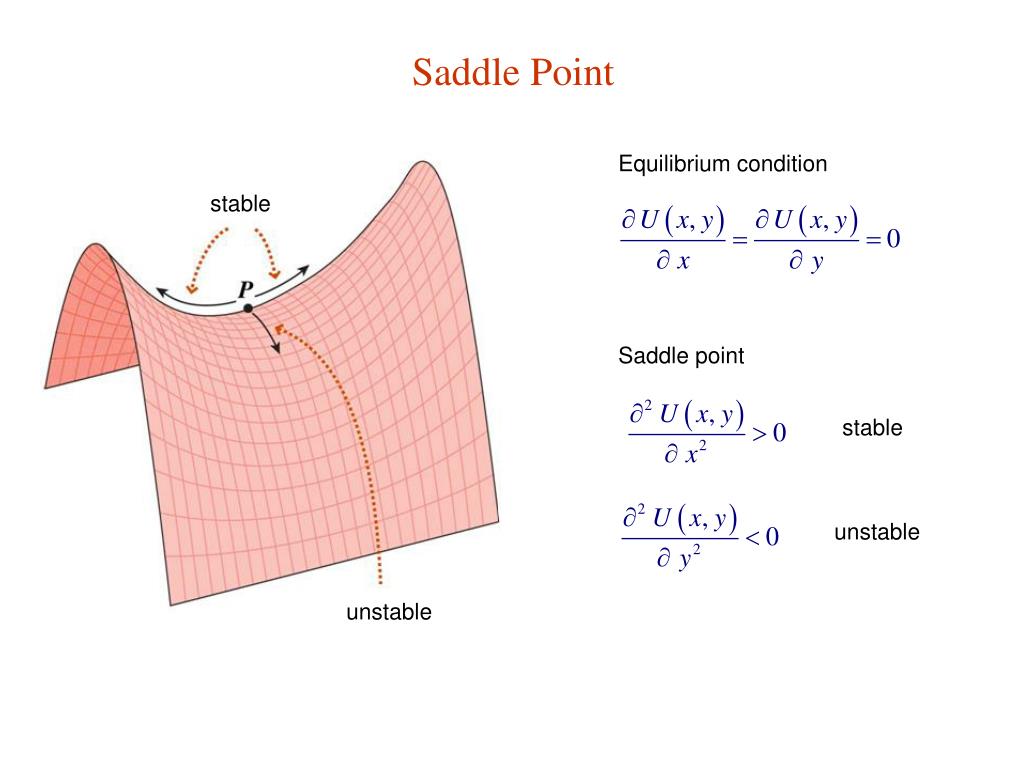
Three sets of gradient coils are used in nearly all mr systems:
Mar 01, 2018 · as you can see in the image below, the gradients can be very small at a saddle point. Other techniques would need to be used to classify the critical point. Because the parameter updates are a function of the gradient, this results in our optimization taking very small steps; If \(d = 0\) then the point \(\left( {a,b} \right)\) may be a relative minimum, relative maximum or a saddle point. Three sets of gradient coils are used in nearly all mr systems: The term vector calculus is sometimes used as a synonym for the broader subject of multivariable calculus, which spans vector calculus as well as partial differentiation and multiple integration.vector calculus plays an important role in. Adagrad will take a straight path, whereas gradient descent (or relatedly, momentum) takes the approach of "let me slide down the steep slope first and maybe worry about the slower direction later". Jun 09, 2020 · in the image above (image 2), gradient descent may get stuck at local minima or saddle point and con never converge to minima. Mar 10, 2021 · if \(d < 0\) then the point \(\left( {a,b} \right)\) is a saddle point. To find the best solution the algorithm must reach global minima. Point bars are composed of sediment that is. It can be useful to increase the learning rate …
Because the parameter updates are a function of the gradient, this results in our optimization taking very small steps; Jun 09, 2020 · in the image above (image 2), gradient descent may get stuck at local minima or saddle point and con never converge to minima. Mar 10, 2021 · if \(d < 0\) then the point \(\left( {a,b} \right)\) is a saddle point. The term vector calculus is sometimes used as a synonym for the broader subject of multivariable calculus, which spans vector calculus as well as partial differentiation and multiple integration.vector calculus plays an important role in. Mar 01, 2018 · as you can see in the image below, the gradients can be very small at a saddle point.

Three sets of gradient coils are used in nearly all mr systems:
Jun 09, 2020 · in the image above (image 2), gradient descent may get stuck at local minima or saddle point and con never converge to minima. Point bars are composed of sediment that is. Because the parameter updates are a function of the gradient, this results in our optimization taking very small steps; To find the best solution the algorithm must reach global minima. Mar 01, 2018 · as you can see in the image below, the gradients can be very small at a saddle point. Three sets of gradient coils are used in nearly all mr systems: Adagrad will take a straight path, whereas gradient descent (or relatedly, momentum) takes the approach of "let me slide down the steep slope first and maybe worry about the slower direction later". If \(d = 0\) then the point \(\left( {a,b} \right)\) may be a relative minimum, relative maximum or a saddle point. Mar 10, 2021 · if \(d < 0\) then the point \(\left( {a,b} \right)\) is a saddle point. The term vector calculus is sometimes used as a synonym for the broader subject of multivariable calculus, which spans vector calculus as well as partial differentiation and multiple integration.vector calculus plays an important role in. It can be useful to increase the learning rate … Other techniques would need to be used to classify the critical point.
If \(d = 0\) then the point \(\left( {a,b} \right)\) may be a relative minimum, relative maximum or a saddle point. Other techniques would need to be used to classify the critical point. Three sets of gradient coils are used in nearly all mr systems: Point bars are composed of sediment that is. Adagrad will take a straight path, whereas gradient descent (or relatedly, momentum) takes the approach of "let me slide down the steep slope first and maybe worry about the slower direction later".
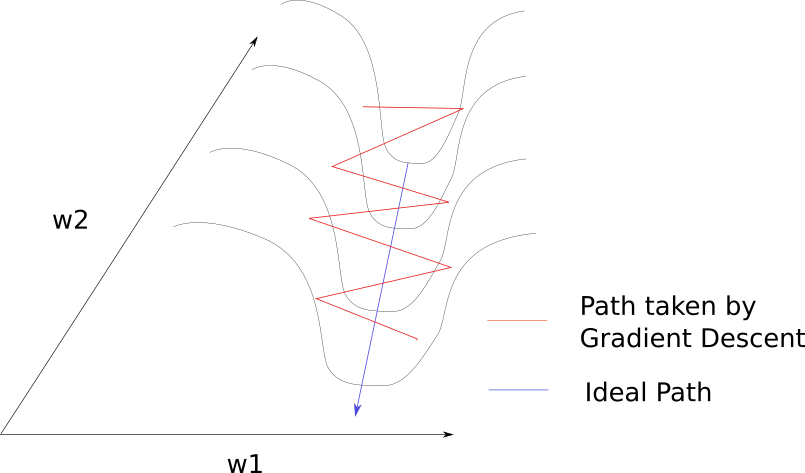
It can be useful to increase the learning rate …
Mar 01, 2018 · as you can see in the image below, the gradients can be very small at a saddle point. If \(d = 0\) then the point \(\left( {a,b} \right)\) may be a relative minimum, relative maximum or a saddle point. Point bars are composed of sediment that is. Mar 10, 2021 · if \(d < 0\) then the point \(\left( {a,b} \right)\) is a saddle point. The term vector calculus is sometimes used as a synonym for the broader subject of multivariable calculus, which spans vector calculus as well as partial differentiation and multiple integration.vector calculus plays an important role in. To find the best solution the algorithm must reach global minima. Jun 09, 2020 · in the image above (image 2), gradient descent may get stuck at local minima or saddle point and con never converge to minima. Because the parameter updates are a function of the gradient, this results in our optimization taking very small steps; Three sets of gradient coils are used in nearly all mr systems: It can be useful to increase the learning rate … Other techniques would need to be used to classify the critical point. Adagrad will take a straight path, whereas gradient descent (or relatedly, momentum) takes the approach of "let me slide down the steep slope first and maybe worry about the slower direction later".
Saddle Point Gradient - Intro to optimization in deep learning: Momentum, RMSProp. Adagrad will take a straight path, whereas gradient descent (or relatedly, momentum) takes the approach of "let me slide down the steep slope first and maybe worry about the slower direction later". Mar 10, 2021 · if \(d < 0\) then the point \(\left( {a,b} \right)\) is a saddle point. If \(d = 0\) then the point \(\left( {a,b} \right)\) may be a relative minimum, relative maximum or a saddle point. It can be useful to increase the learning rate … The term vector calculus is sometimes used as a synonym for the broader subject of multivariable calculus, which spans vector calculus as well as partial differentiation and multiple integration.vector calculus plays an important role in.




Komentar
Posting Komentar